Web Scraper - Getting Started

Introduction
You can easily use the Web Scraper node from Byteline to extract content and data from a website. In this documentation, you will understand how to extract data from any website using its underlying HTML to specify the elements you want to extract. We will use the Byteline Web Scraper Chrome Extension for configuring the data to be scraped.
For this documentation, we are assuming a flow is initiated with a simple scheduler node, but it is to be noted that you can use a web scraper node with any trigger. For more details, you can check How to Create your First Flow Design.
Follow the steps outlined below to extract data from any website.
Configure
1. Click "Flow designer"
2. Click "Create flow"
3. Select a trigger. We're using Scheduler for this example.
4. Select the Scheduler node in the Flow Designer to configure.
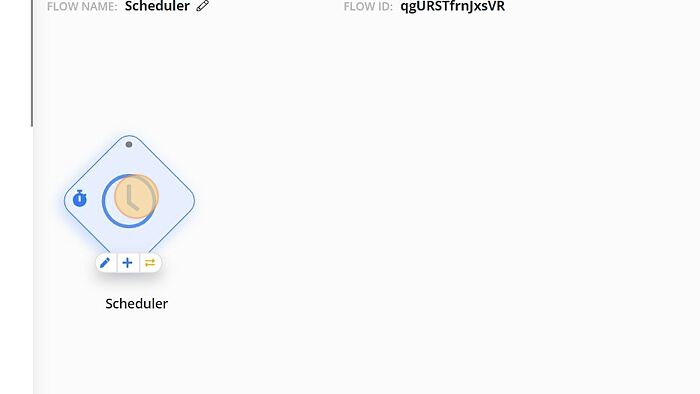
5. Configure to your preferences.
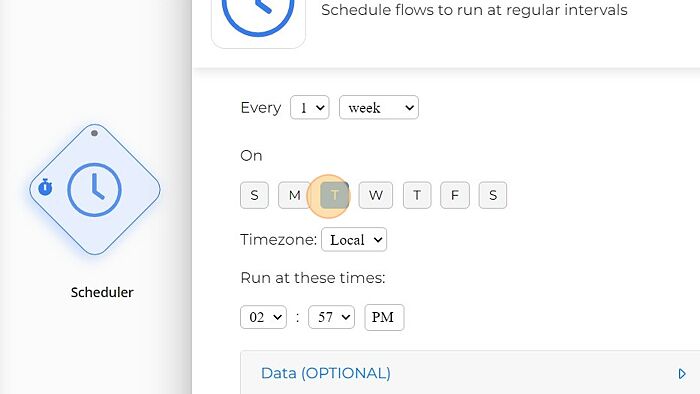
6. Click this checkbox.
7. Click "Save"
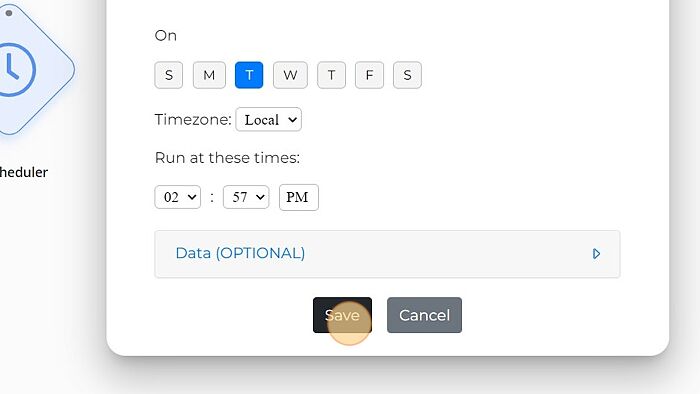
8. Add another node by clicking the '+' sign on the Scheduler node.

9. Click "Web Scraper"
10. Select the Web Scraper node on the Flow Designer.
11. We're scraping from clutch.co to find a web designer that specializes in the dental industry and has more than 5 reviews.
12. Paste the clutch.co link here. Reference: https://clutch.co/directory/mobile-application-developers?industries=field_pp_if_dental&related_services=field_pp_sl_web_design&reviews=5
13. Click "https://clutch.co/directory/mobile-application-developers?industries=field_pp_if_dental&related_services=field_pp_sl_web_design&reviews=5"
12. Once you have installed the Byteline Web Scraper Chrome Extension found here, you can enable it to begin capturing elements.
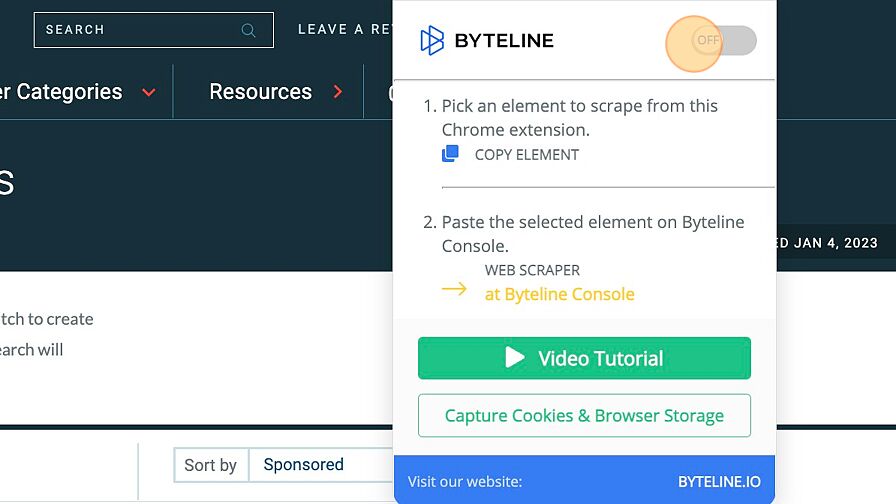
13. Select the 'Capture List Elements' for our example. If you are capturing a single on page element- select 'Capture Single Element'.

14. Select the repeating element to be extracted. Note: the highlighted elements will be displayed in a light orange/yellow.

15. Click "Paste from the Chrome Extension"
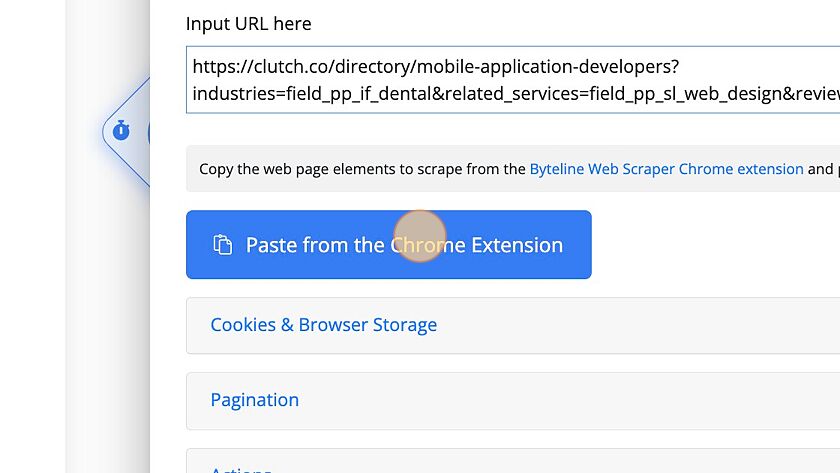
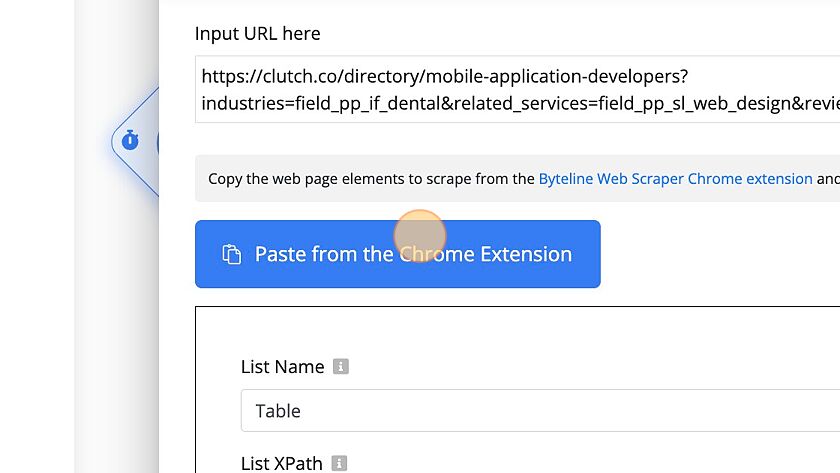
16. Name the table and fields. Names need to be a single word.

17. Capture the URL by selecting Link

18. Click "Paste from the Chrome Extension"
19. Click "Test run"
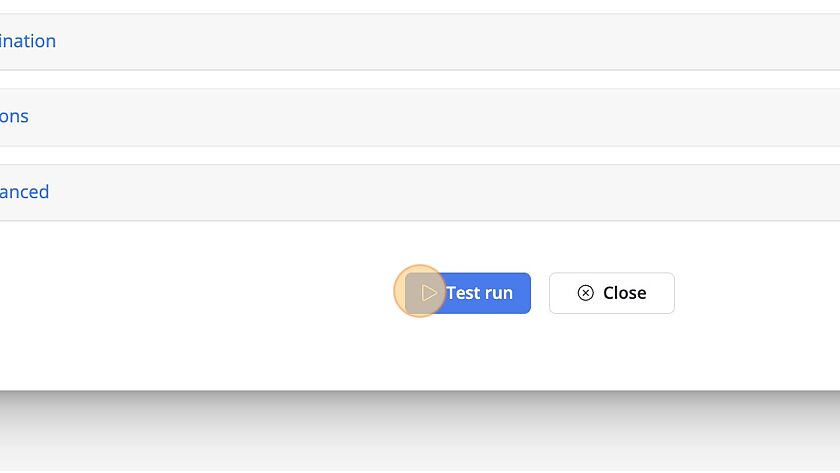
20. Confirm the output and either modify the scraper by selecting "Go Back", Add another node or Close to proceed.
21. All data can be extracted by selecting "Run Now". Note: Once this flow is live it will run as scheduled.
22. View the output by selecting the "i".

Scraping behind a login wall
Byteline has added support to scrape pages behind a login wall. It works by using the Byteline Web Scraper Chrome extension to copy the cookies and then paste them on the Byteline Console. Please follow the below steps:
Copying Cookies using the Chrome extension
- Login to the website to scrape and go to the web page for which you're configuring the scraper.
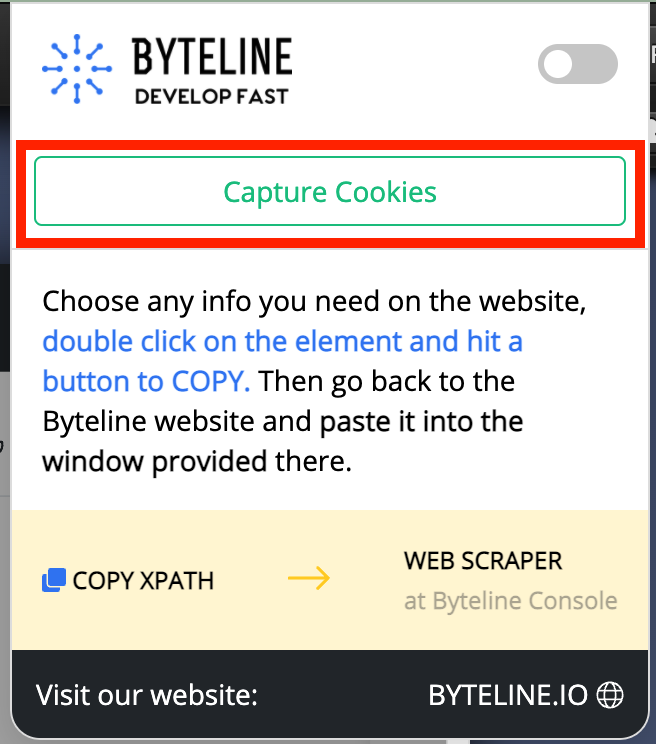
- Click on the Byteline Web Scraper Chrome extension installed on your Chrome browser, and then hit the "Capture Cookies" buttonYou don't need to enable the toggle button to capture cookies
Pasting Cookies on the Byteline Console
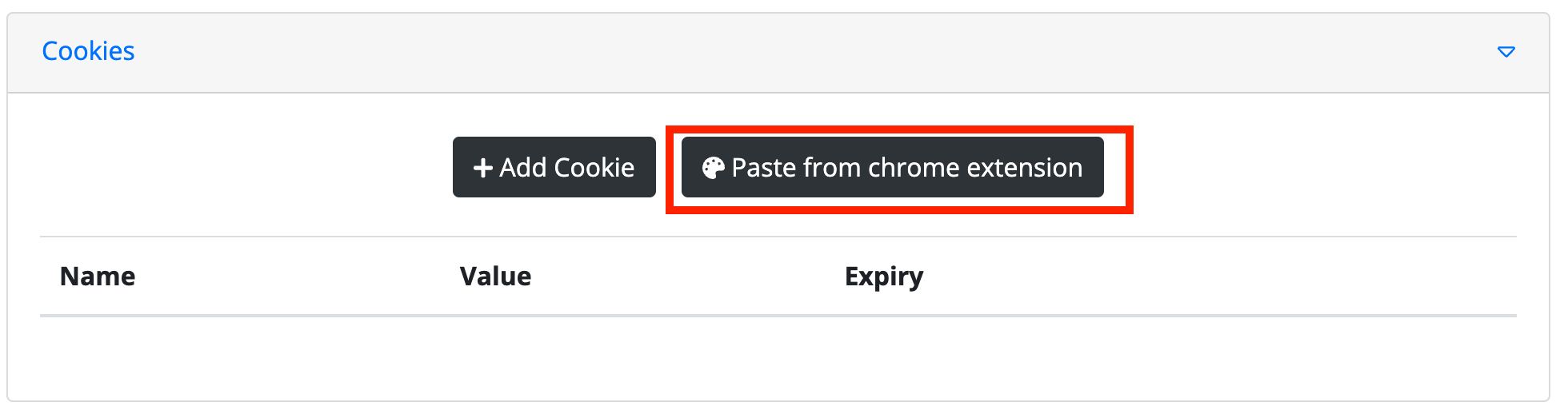
Now go to the Byteline Console, open your flow, and edit the web scraper task. Go to the Cookies tab, and click on the "Paste from chrome extension" button.
That's it! Now when you run the flow, it can scrape the data behind the login wall.
Scraping a list of URLs
You can scrape a list of URLs in the following ways:
- Configure Scheduler Trigger node with data retrieved from a Google Spreadsheet. You can then use any Spreadsheet column in the Web Scraper URL field. For step-by-step instructions, check out how to build a lists crawler use case page.
- Retrieve a list of URLs from any Byteline integration e.g., Airtable, and then use the Byteline loop over in the Web Scraper config.
Using expressions for the URL field
You can either an expression to specify the complete URL, as below.

Or you can just specify the changing part of the URL using an expression, such as below

Pagination
Web Scraper supports the pagination method that lets you scrape multiple pages from a website.
Pagination is used when all data is not on a single page. There is a certain pagination mechanism based on which you get the first page, then the second page, then the third page, and so on.
Web Scraper supports three different types of pagination.
- Horizontal Scrolling
- Vertical Scrolling
- Infinite Scrolling

Pagination - Horizontal Scrolling
Horizontal scrolling is used for websites where you have to scroll pages horizontally to access more data.
Step 1: Go to the website and enable the Byteline Web Scraper Chrome extension.

Step 2: Double click on the next page link/button.

Step 3: Select the Text radio button, and click the Single Element button to copy the XPath.

Step 4: Paste the XPath in the Next page button/link XPath box.

Step 5: Select the maximum number of pages you want to scrape.

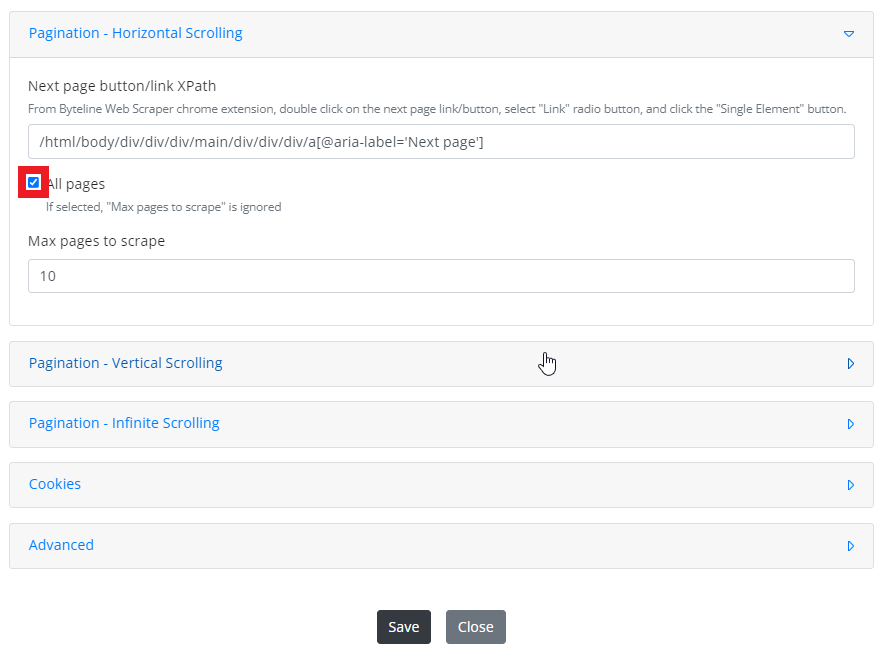
Step 6: Click on the Save button to save the changes.

Pagination - Vertical Scrolling
Vertical scrolling is used for websites where you have to scroll pages vertically to access more data.
Step 1: Go to the website and enable the Byteline Web Scraper Chrome extension.

Step 2: Double click on the next page link/button.

Step 3: Select the Text radio button, and click the Single Element button to copy the XPath.
Step 4: Paste the XPath in the Next page button/link XPath box.

Step 5: Select the maximum number of pages you want to scrape.


Step 6: Click on the Save button to save the changes.

Pagination - Infinite Scrolling
Infinite scrolling is used for websites where you have to scroll pages infinitely to access more data. It is used to scrape data from websites like Twitter, Facebook, Quora, and other sites alike. In simple words, it is used in such cases where pages keep on loading with scrolling.
With infinite scrolling there is no button to click, so you just need to enable the scroll by clicking on the box before Enable Infinite Scrolling.


Once done, click on the Save button to save the changes.

You have successfully saved your pagination settings.
Troubleshooting
Copy to clipboard doesn't work
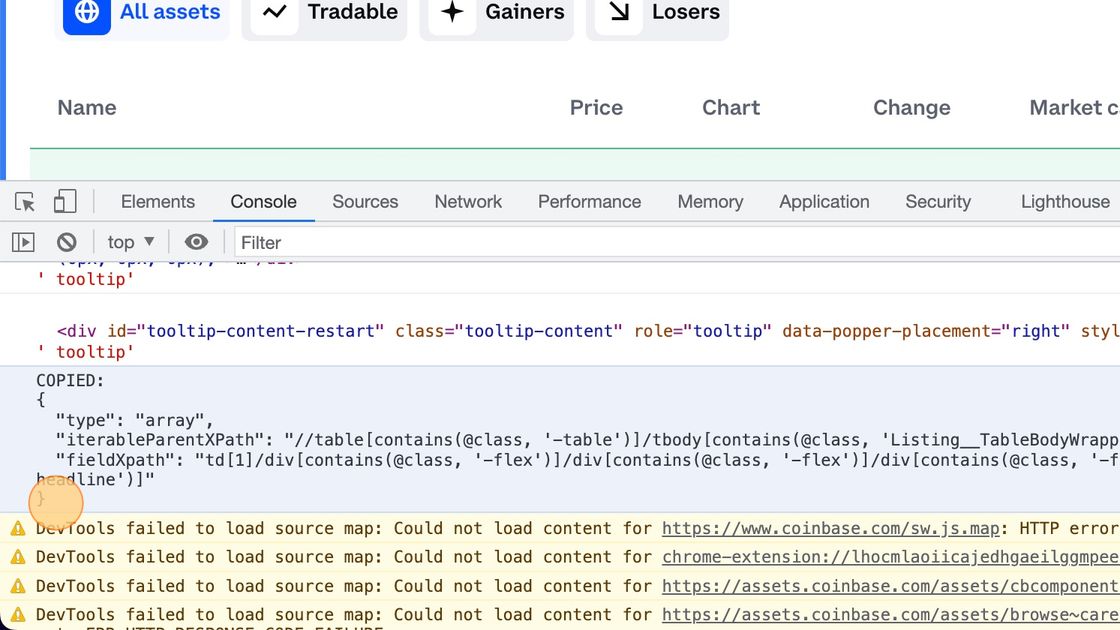
A few sites restrict copying data to the clipboard. For these sites, the Chrome extension says XPath copied successfully, but it's not. The good news is that the selected XPath is also printed to the developer console, so you can manually copy it to the web scraper task on the Byteline Console.
The copied XPath printed in the console has two formats depending on if it's for the Capture List Element or Capture Single Element.
Capture List Element format
COPIED:
{
"type": "array",
"iterableParentXPath": "//div[contains(@class, 'filtered-content')]/div[contains(@class, 'list')]/div[contains(@class, 'column')]",
"fieldXpath": "article/a[contains(@class, '-group')]/div[contains(@class, 'relative')]/p[contains(@class, 'uppercase')]"
}
Mapping to Scraper Configuration:
iterableParentXPath -> List XPath on the scraper task configuration
fieldXpath -> field name XPath on the scraper task configuration
Capture SIngle Element format
COPIED:
{
"type": "scalar",
"xpath": "//section[contains(@class, '-group')]/header[contains(@class, 'text-center')]/h1[contains(@class, '-bottom')]"
}
Mapping to Scraper Configuration:
xpath -> field XPath on the scraper task configuration
Step-by-step instructions:
1. Click here
Right-click on the page
Click "Inspect"

2. Click the Console tab
3. Copy the text